几何模型¶
思维导图¶
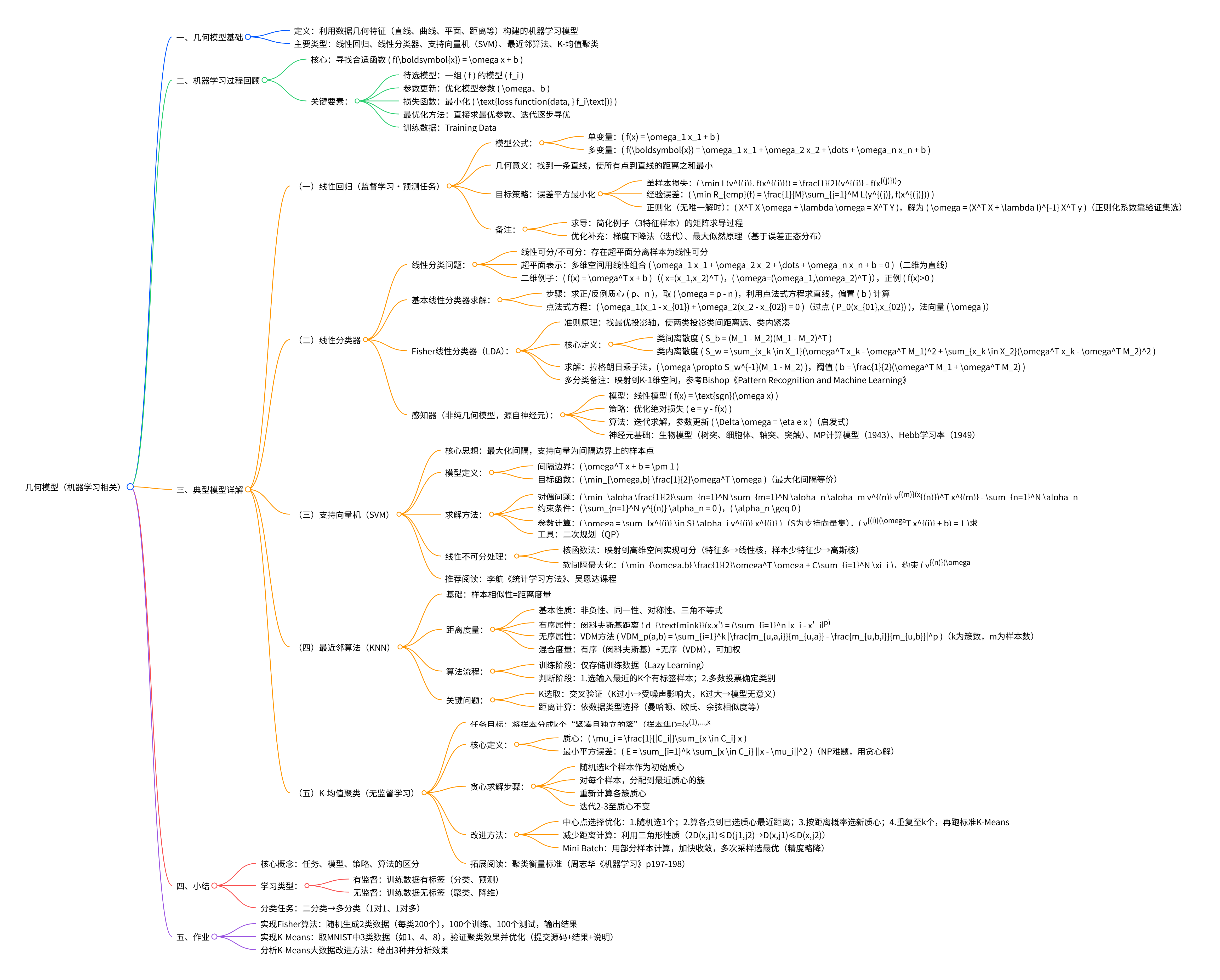
一、几何模型基础概念¶
1. 定义与核心思想¶
- 几何模型:利用直线、曲线、平面、距离等几何特征构建的机器学习模型,核心是通过几何关系区分样本分布特征。
- 典型模型类别:线性回归、线性分类器、支持向量机、最近邻算法、K-均值聚类。
2. 机器学习过程回顾¶
- 核心目标:找到合适的函数\(f(x)=\omega x + b\),通过更新参数\(\omega\)和\(b\)最小化损失函数。
- 优化方法:直接求解最优参数的解析法、逐步迭代的梯度下降法等。
- 损失函数与风险:以误差平方损失函数为例,目标为最小化经验风险\(R_{emp}(f)=\frac{1}{M}\sum_{j=1}^{M}L(y^{(j)},f(x^{(j)}))\)。
二、典型几何模型详解¶
(一)线性回归模型¶
- 模型形式:单变量\(f(x)=\omega_1 x_1 + b\);多变量\(f(\pmb{x})=\omega_1 x_1 + \omega_2 x_2 + \dots + \omega_n x_n + b\)。
- 几何意义:找到一条直线(或超平面),使所有样本点到直线的距离之和最小。
- 求解方法:通过最小化误差平方和构建线性方程组,满秩时直接求解;否则引入正则化项\(\lambda\),得\(\omega=(X^T X + \lambda I)^{-1} X^T y\)。
(二)线性分类器¶
1. 基本线性分类器¶
- 模型形式:二维空间\(f(x)=\omega^T x + b\),通过正负例质心求解法向量\(\omega=p-n\)和偏置\(b\)。
- 分类逻辑:\(f(x)>0\)为正例,\(f(x)<0\)为负例,决策面为线性超平面。
2. Fisher线性分类器(LDA)¶
- 核心准则:寻找最优投影轴,使两类样本投影的类间距离最大、类内紧凑度最高。
- 关键计算:类间离散度\(S_b=(M_1-M_2)(M_1-M_2)^T\)、类内离散度\(S_w\),通过拉格朗日乘子法求解最优投影向量\(\omega=S_w^{-1}(M_1-M_2)\)。
- 阈值确定:\(b=\frac{1}{2}(\omega^T M_1 + \omega^T M_2)\)。
(三)支持向量机(SVM)¶
- 核心思想:最大化两类样本到决策面的间隔,仅由支持向量(间隔边界上的样本)决定决策面。
- 优化目标:最小化\(\frac{1}{2}\omega^T \omega\),约束条件为\(y^{(n)}(\omega^T x^{(n)} + b) \geq 1\)。
- 求解方法:转化为对偶问题,通过拉格朗日乘子法和二次规划(QP)求解,得\(\omega=\sum_{x^{(i)} \in S}\alpha_i y^{(i)} x^{(i)}\)。
- 扩展处理:线性不可分问题采用核函数法(映射到高维空间)或软间隔最大化(引入松弛变量\(\xi_i\))。
(四)最近邻算法(KNN)¶
- 核心逻辑:基于样本相似性分类,属于lazy learning(无显式训练过程,仅存储训练数据)。
- 分类步骤:选择输入样本的K个最近邻标签样本,按多数投票原则确定输入类别。
- 关键问题:K值选择(通过交叉验证确定)、距离度量(有序属性用闵科夫斯基距离,无序属性用VDM方法)。
(五)K-均值聚类¶
- 任务目标:无监督学习,将样本划分为k个“紧凑且独立”的簇。
- 核心定义:簇质心\(\mu_i=\frac{1}{|C_i|}\sum_{x \in C_i}x\),目标最小化簇内平方误差\(E\)。
- 求解步骤:随机初始化k个质心→迭代分配样本到最近质心→更新质心→直至质心稳定(贪心算法近似求解NP难题)。
三、关键支撑技术¶
1. 距离度量方法¶
- 基本性质:非负性、同一性、对称性、三角不等式。
- 具体类型:有序属性(闵科夫斯基距离,含曼哈顿距离\(p=1\)、欧氏距离\(p=2\));无序属性(VDM方法);混合属性(加权结合有序与无序属性距离)。
2. 任务与模型拓展¶
- 任务区分:有监督学习(分类、回归,需标签样本);无监督学习(聚类,无需标签样本)。
- 多分类实现:通过1对1或1对多方式,利用多个二分类器组合完成。
3. K-均值聚类改进方法¶
- 初始化优化:按距离概率选择初始质心,提升聚类稳定性。
- 计算优化:利用三角形性质减少距离计算量;Mini Batch采样加快收敛(牺牲部分精度)。
四、小结与实践要求¶
1. 核心要点¶
- 掌握机器学习“任务-模型-策略-算法”的核心框架,理解几何模型的优化逻辑。
- 区分有监督与无监督学习的适用场景,学会用简单几何模型解决二分类任务。
2. 实践任务¶
- 实现Fisher算法:随机生成两类数据(每类200个),分训练集(100个)与测试集(100个)验证效果。
- 实现K-均值算法:选取MNIST数据集3类数据进行聚类,分析并优化效果。
- 分析K-均值大数据改进方法:阐述3种改进方案及效果。
五、几何模型核心公式与求解步骤对照表¶
| 模型名称 | 核心公式 | 求解步骤 |
|---|---|---|
| 单变量线性回归 | 1. 模型:\(f(x)=\omega_{1}x_{1}+b\) 2. 损失函数:\(min L=\frac{1}{2}\sum_{j=1}^{M}(y^{(j)}-\omega x^{(j)}-b)^2\) 3. 正则化解:\(\omega=(X^TX+\lambda I)^{-1}X^TY\) |
1. 确定目标:最小化误差平方和(经验风险); 2. 对ω和b求导或引入正则化(解决欠秩); 3. 解线性方程组得到最优参数ω和b。 |
| 多变量线性回归 | 1. 模型:\(f(\pmb{x})=\omega_1x_1+\omega_2x_2+\dots+\omega_nx_n+b\) 2. 矩阵形式损失:\(min L=\frac{1}{2}(Y-X\omega)^T(Y-X\omega)\) |
1. 构建多变量线性模型和矩阵形式损失函数; 2. 若X满秩直接解方程\(X^TX\omega=X^TY\),否则加正则化; 3. 计算得到参数向量ω和偏置b。 |
| 基本线性分类器 | 1. 模型:\(f(x)=\omega^Tx+b\)(\(\omega=(\omega_1,\omega_2)^T\)) 2. 法向量:\(\omega=p-n\) 3. 偏置:\(b=-\omega^T\frac{p+n}{2}\) |
1. 计算正例质心p和负例质心n; 2. 以两质心差为法向量ω; 3. 利用质心中点在决策面的性质求偏置b; 4. 得到分类决策边界。 |
| Fisher线性分类器 | 1. 投影:\(y=\omega^Tx\) 2. 类间离散度:\(S_b=(M_1-M_2)(M_1-M_2)^T\) 3. 类内离散度:\(S_w=S_1+S_2\) 4. 最优ω:\(\omega=S_w^{-1}(M_1-M_2)\) 5. 阈值:\(b=\frac{1}{2}(\omega^TM_1+\omega^TM_2)\) |
1. 计算两类样本的均值\(M_1、M_2\)和类内离散度矩阵\(S_w\); 2. 构造准则函数\(J(\omega)=\frac{\omega^TS_b\omega}{\omega^TS_w\omega}\); 3. 用拉格朗日乘子法求ω的最优解; 4. 计算分类阈值b,完成投影分类。 |
| 支持向量机(硬间隔) | 1. 目标函数:\(min_{\omega,b}\frac{1}{2}\omega^T\omega\) 2. 约束:\(y^{(n)}(\omega^Tx^{(n)}+b)\geq1\) 3. 对偶问题:\(min_\alpha\frac{1}{2}\sum_{n,m}\alpha_n\alpha_my^{(n)}y^{(m)}(x^{(n)})^Tx^{(m)}-\sum_n\alpha_n\) 4. 最优ω:\(\omega=\sum_{x\in S}\alpha_iy^{(i)}x^{(i)}\) |
1. 构建硬间隔最大化目标函数和约束条件; 2. 转化为对偶问题(引入拉格朗日乘子); 3. 用二次规划(QP)求解对偶问题得α; 4. 由非零α对应的支持向量计算ω和b; 5. 确定决策边界。 |
| 支持向量机(软间隔) | 1. 目标函数:\(min_{\omega,b}\frac{1}{2}\omega^T\omega+C\sum_i\xi_i\) 2. 约束:\(y^{(n)}(\omega^Tx^{(n)}+b)\geq1-\xi_i,\xi_i\geq0\) |
1. 引入松弛变量\(\xi_i\)允许少量误分类; 2. 构建含惩罚参数C的目标函数和约束; 3. 转化对偶问题并求解α; 4. 计算ω和b,得到鲁棒性决策边界。 |
| K均值聚类 | 1. 质心:\(\mu_i=\frac{1}{\|C_i\|}\sum_{x\in C_i}x\) 2. 平方误差:\(E=\sum_{i=1}^k\sum_{x\in C_i}\|x-\mu_i\|^2\) |
1. 随机选择k个样本作为初始质心; 2. 计算每个样本到各质心的距离,分配到最近簇; 3. 重新计算各簇质心; 4. 迭代步骤2-3,直至质心稳定。 |